-
API Latency를 줄이는 방법 (Part. 3)극락코딩 2024. 11. 14. 23:19
API의 응답속도 및 지연에 민감한 서비스인 경우, 어떤 방식으로 latency를 줄일 수 있을까?
이전 게시글에서는 전통적인 M-threads 기법으로 API의 Latency를 줄이도록 구현하였다. 속도면에서는 많은 이점을 얻었지만, 다수의 스레드가 낭비되고 이에 대한 처리에 복잡함이 있었다.
이번에는 코루틴을 기반으로 동시성 및 병렬처리 작업을 진행하겠습니다.
TestController에 V3 API를 추가한다.
/** with Coroutines */ @GetMapping("/api/ral/v3/test") suspend fun getTestV3( request: TestRequest ) = testV3Service.getTestV3(request).wrap()자, 그럼 서비스로 가보자
@Service class TestV3Service( private val test1Repository: Test1Repository, private val test2Repository: Test2Repository, private val test3Repository: Test3Repository, private val test4Repository: Test4Repository, private val cacheService: CacheService, private val mathEngine: MathEngine, private val googleClient: GoogleClient, ) { suspend fun getTestV3(request: TestRequest): TestResponse { return coroutineScope { /** Database */ val test1Model = async(Dispatchers.IO) { test1Repository.findAllById(request.test1Id).map { test1 -> Test1Model.from(test1) } } val test2Model = async(Dispatchers.IO) { test2Repository.findAllById(request.test2Id).map { test2 -> Test2Model.from(test2) } } val test3Model = async(Dispatchers.IO) { test3Repository.findAllById(request.test3Id).map { test3 -> Test3Model.from(test3) } } val test4Model = async(Dispatchers.IO) { test4Repository.findAllById(request.test4Id).map { test4 -> Test4Model.from(test4) } } /** Redis Cache */ val test1Cache = async(Dispatchers.IO) { cacheService.get("test1:key:${request.test1Id}") } val test2Cache = async(Dispatchers.IO) { cacheService.get("test2:key:${request.test2Id}") } val test3Cache = async(Dispatchers.IO) { cacheService.get("test3:key:${request.test3Id}") } val test4Cache = async(Dispatchers.IO) { cacheService.get("test4:key:${request.test4Id}") } /** Cpu Logic */ val result1 = async(Dispatchers.Default) { mathEngine.execute() } val result2 = async(Dispatchers.Default) { mathEngine.execute() } val result3 = async(Dispatchers.Default) { mathEngine.execute() } val result4 = async(Dispatchers.Default) { mathEngine.execute() } /** WebClient Api Call */ val realTrend1 = async(Dispatchers.IO) { googleClient.getRealTimeTrends() } val realTrend2 = async(Dispatchers.IO) { googleClient.getRealTimeTrends() } val realTrend3 = async(Dispatchers.IO) { googleClient.getRealTimeTrends() } val realTrend4 = async(Dispatchers.IO) { googleClient.getRealTimeTrends() } TestResponse.of( cacheModel = TestCacheModel( test1 = test1Cache.await(), test2 = test2Cache.await(), test3 = test3Cache.await(), test4 = test4Cache.await() ), test1s = test1Model.await(), test2s = test2Model.await(), test3s = test3Model.await(), test4s = test4Model.await(), result = listOf(result1.await(), result2.await(), result3.await(), result4.await()), trendModels = listOfNotNull( realTrend1.await(), realTrend2.await(), realTrend3.await(), realTrend4.await() ) ) } } }이전에 CompletableFuture를 쓸때는 어노테이션을 사용해야 해서, 별도로 클래스를 분리하였었다.
하지만 이번에 코루틴을 사용할때는 별도의 분리가 필요없다.
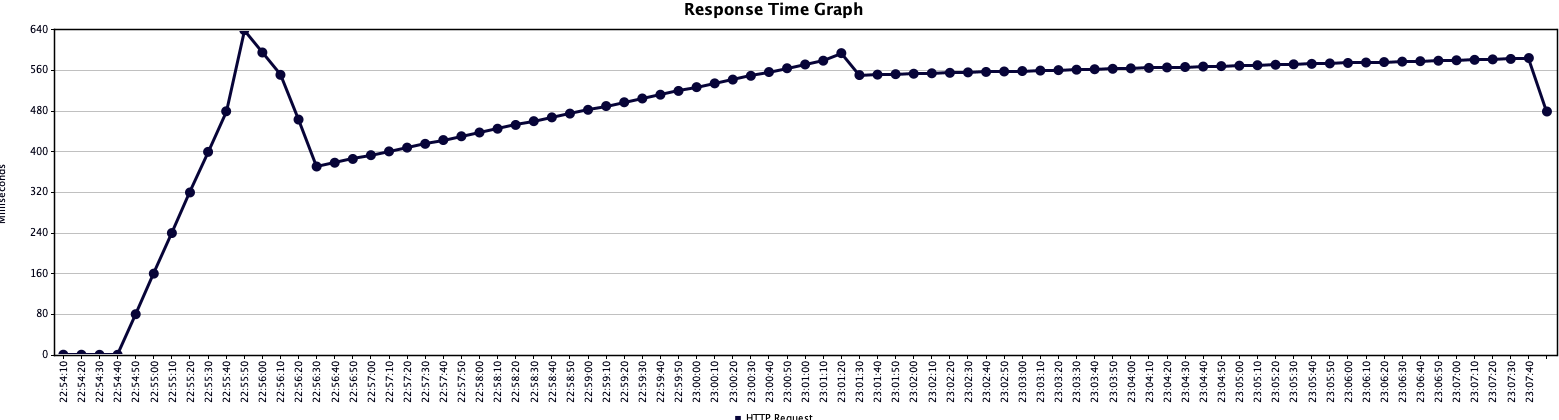
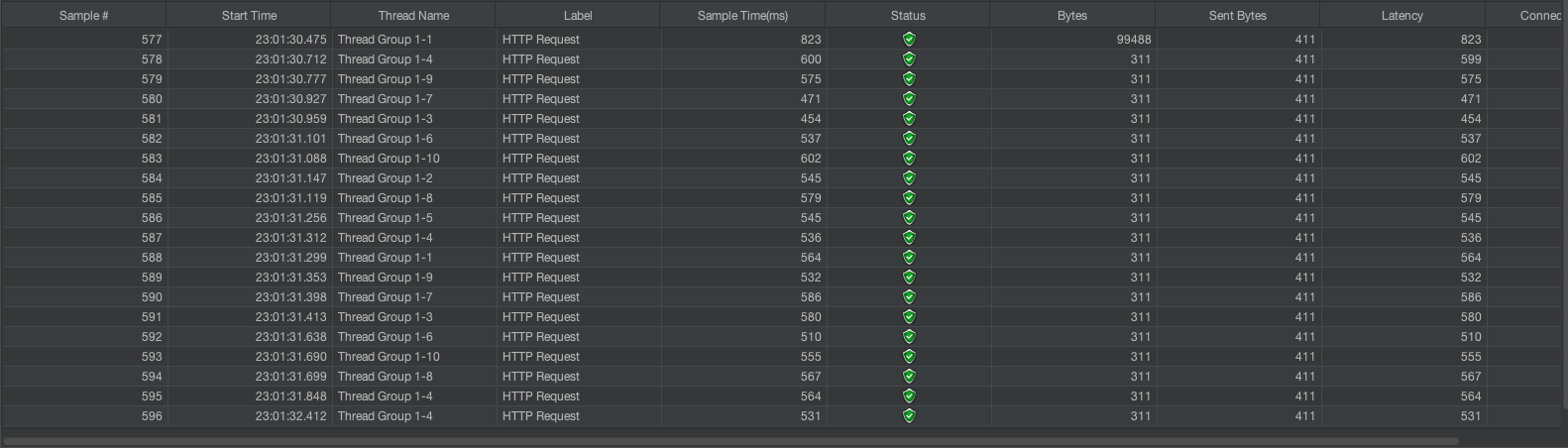
PC를 몇번 바꿔서 그렇더니, 지표가 살짝 다르긴 한다.
하지만 확실히 기존처리에 비해 아주 조금의 성능향상을 볼 수 있다.
하지만 제일 중요한 것은!!
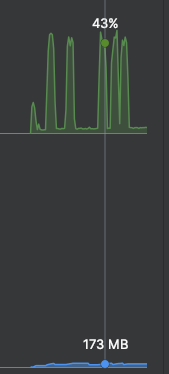
위는 CPU, 아래는 Heap Memory다. 엄청나게 많은 요청을 진행했음에도 확실히 CPU와 Memory를 적게 먹는 것을 확인할 수 있다.
Reference'극락코딩' 카테고리의 다른 글
springboot v3.x에서 swagger v3 설정법 (1) 2023.11.27 spring version up을 진행할때 참고하기 (0) 2023.11.06 API Latency를 줄이는 방법 (Part. 1) (0) 2023.08.29 API Latency를 줄이는 방법 (Part. 0) (0) 2023.08.28 Slack Message 발송 (1) 2023.08.27